https://www.iqt.org/per-packet-scalable-switch-policy-controls-with-dovesnap/
FAUCET for IXes
Experimental FAUCET support for OpenBSD
OpenBSD has a built in OpenFlow switch. It doesn’t support FAUCET in released code, but there is experimental support with a kernel patch.
https://github.com/anarkiwi/faucet/blob/openbsd/docs/vendors/openbsd/README_OpenBSD.rst
Bending Network Reality: Merging Virtual and Physical Networks with Dovesnap
Adding new switch hardware support to FAUCET
Every now and then, I’m asked – how can switch vendor add support for FAUCET?
The best way to understand how FAUCET uses OpenFlow, is to use the test suite.
However, some current FAUCET vendors and developers have been kind enough to share their experiences about how to make FAUCET run on hardware:
Remote mirroring and coprocessing
If you have a FAUCET stack network, with potentially many switches, it would sure be nice to have a way to be able to mirror any port on any switch, and have that traffic show up on one port on one switch.
You can do this, across multiple vendor switches, by combining several FAUCET features – tunneling, coprocessing – and a hardware loopback coprocessor.
Here’s our scenario. We have two switches in our FAUCET stack. We want to mirror any port on any switch and have that traffic appear on port 12 on DP 1. In our example below, we’ve chosen to mirror the host on DP 2, port 3.
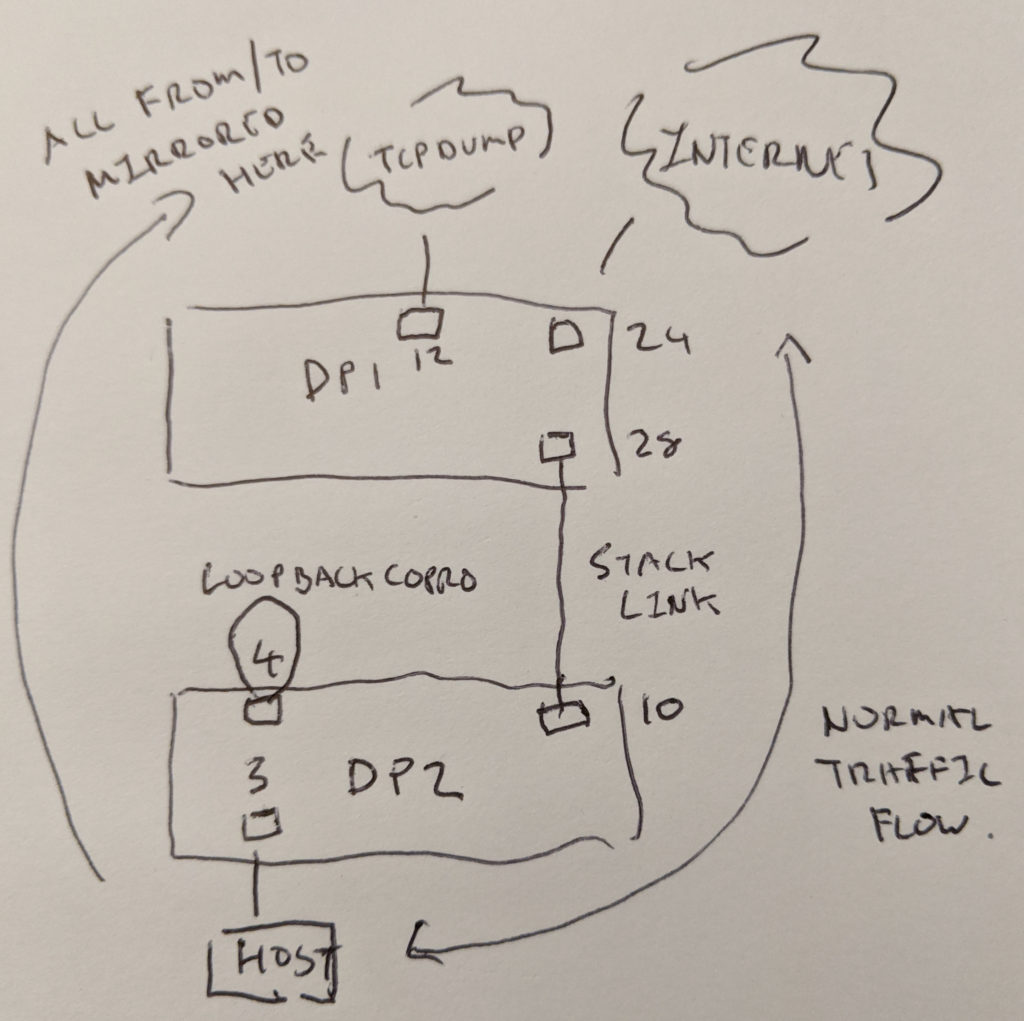
Here’s the config for DP1:
dps:
dp1:
dp_id: 1
stack:
priority: 1
interfaces:
12:
output_only: true
24:
tagged_vlans:
- untrusted
28:
stack:
dp: dp2
port: 10
And here’s the config for DP2:
dps:
dp2:
dp_id: 2
interfaces:
3:
native_vlan: untrusted
4:
acls_in: [remotemirror]
coprocessor:
strategy: vlan_vid
mirror: [3]
10:
stack:
dp: dp1
port: 28
acls:
remotemirror:
rules:
- rule:
vlan_vid: 333
actions:
allow: 0
- rule:
actions:
allow: 0
output:
tunnel:
type: vlan
tunnel_id: 333
dp: dp1
port: 12
Essentially, traffic from the host on DP 2 port 3 is switched on the untrusted VLAN as normal.
However, we want to now mirror DP port 3. So we add the mirror configuration to port 4 (we could add as many ports for mirroring to this same port 4 as we like).
Traffic to and from port 3, is sent to port 4 (per standard FAUCET mirroring). That traffic is looped back in port 4, where it is subjected to the remote mirror ACL. The last rule in that ACL adds VLAN 333 to that traffic which then enters a FAUCET tunnel. The destination of that tunnel is DP 1, port 12 (FAUCET takes care of the details of getting that traffic delivered over the stacking topology).
The first rule is present to prevent accidents – a packet entering the loop cable again with VLAN 333 would be repeatedly relooped, and we wouldn’t want that!
If you have a switch with a roomy action budget, then it would be convenient not to need the loopback plug – a future FAUCET version will allow you to do this. However this solution accommodates most all switches and can be used to implement centralized mirroring and coprocessing today.
Coprocessing with a passive loopback cable
This rather ugly, but dramatically lit little fellow is a passive loopback cable (I connected only two pairs, so it can do only 100MB).

Here it is installed in port 11 on this OpenFlow switch.

But why? What possible use is this beyond testing that the physical interface works?
Some OpenFlow switch implementations are based on hardware that predates the SDN era. In other words, some of that hardware just isn’t very programmable. There are limits on what actions some hardware can perform, and in some cases even the number of actions. If you need more than that – well – tough luck, it can’t be done (or it can only be done in software).
What if you can spare a port though?
That’s what we’re doing here. We’re using a coprocessing port to send packets out the loopback. As they come back, they hit a FAUCET ACL which allows further processing. The round trip buys us a bigger action budget – we can spend actions on the way out, and on the way in again.
acls:
pushit:
- rule:
actions:
output:
vlan_vid: 999
port: 24
dps:
mydp:
interfaces:
11:
description: loopback
coprocessor:
strategy: vlan_vid
acls_in: [pushit]
mirror:
- 13
13:
native_vlan: trusted
24:
tagged_vlans:
- trusted
- untrusted
Port 13 is a simple port with one native VLAN. Traffic to and from this port is mirrored to port 11 (the mirror operation consumes our hardware action budget). Those packets leave on port 11, are looped back to port 11, where they hit the pushit ACL. This ACL pushes a new VLAN, 999 and outputs to 24. That ACL also consumes the hardware action budget (so without the loopback we would not have have had the hardware resources to complete the entire operation).
A perfect beautiful solution? No. But, an interesting way to make less capable hardware somewhat more programmable by adding more (completely passive) hardware.
APNIC blog: why network engineers should code
Connecting Containers to Faucet
One of the installation paths for Faucet is to run inside of a Docker container and happily control an OpenFlow network of both physical and virtual switches. However, what about using Faucet to control the network of Docker containers themselves? You might be asking yourself right about now why you would even want to do that though. One of the motivations behind it is to be able to restrict L2 connectivity between containers just like Faucet lets you do with a hardware switch. In a hybrid world where containers, virtual machines, and bare metal servers all have their own MAC addresses and IP addresses on the same network, having a single centralized controller for routing, access control, monitoring, and management of that network makes for an appealing option.
Docker networking is a complex beast and has made different iterations over the years. One of the current patterns that seems to have stuck is the use of Docker Networking Drivers. These drivers are particularly nice because it allows developers to write their own plugins that can be used to create networks that containers attach to, without having to hack, wrap, or otherwise change Docker directly.
One of the early examples of such a driver was from Weaveworks, who wrote this, which was the inspiration for other developers and companies to start writing their own plugins that integrated their own variations of networking that folks might want to attach containers to. One such group were the folks behind gopher-net who wrote an Open vSwitch network plugin for Docker.
Hey, now we’re on to something, Faucet already works with Open vSwitch! After taking a poke at the existing code base, now approaching 5 years being stale, it seemed like the right path forward was forking the project and modernizing the packages and making it Faucet friendly. So that’s exactly what we did. Introducing dovesnap.
With dovesnap, connecting containers to a Faucet controlled network is a breeze. Dovesnap uses docker-compose to build and start the containers used for Open vSwitch itself and the plugin that interfaces with Docker. The following are the basic steps to get it up and running:
First, make sure you have the Open vSwitch kernel module loaded:
$ sudo modprobe openvswitchNext, clone the repo, start the service, and verify that it is up:
$ git clone https://github.com/cyberreboot/dovesnap
$ cd dovesnap
$ docker-compose up -d --build
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
2048530e312a cyberreboot/dovesnap "dovesnap -d" 11 minutes ago Up 30 seconds dovesnap_plugin_1_115df2016fd9
ddbd1fcd6148 openvswitch:2.13.0 "/usr/bin/supervisord" 11 minutes ago Up 30 seconds (healthy) dovesnap_ovs_1_d0a0cee6f49dNow create a network with our new ovs driver (note you can make as many of these as you like as long as they don’t have overlapping IP space):
$ docker network create mynet -d ovs -o ovs.bridge.mode=nat -o ovs.bridge.dpid=0x1 -o ovs.bridge.controller=tcp:127.0.0.1:6653 --subnet 172.12.0.0/24 --ip-range=172.12.0.8/29 --gateway=172.12.0.1
2ce5e00010331ec9115afd0adfc972a3beb530d3086bea20932e5edc85cfa4deIn this example we included a lot of options, but the only ones necessary are:
-d ovs (for the driver)
-o ovs.bridge.controller=tcp:127.0.0.1:6653 (so that it can connect to Faucet)
By default, creating a network with this driver will use “flat” mode, which means no natting and you’ll need to connect a network interface as a port on the OVS bridge for routing (i.e. -o ovs.bridge.add_ports=enx0023569c0114). For this example, we chose the “nat” mode which will use natting and not require routing from another interface. Additionally, we’ve supplied the DPID for the bridge making it easy to add to the Faucet config. Lastly, we have set what subnet, IP range, and gateway it should create and use.
Finally with our network created, we can start up containers that are attached to it:
$ docker run -td --net=mynet busybox
205e47b076195513a54b98ea78c4c449c5ac403371508e457a6631f64c0c3596
$ docker run -td --net=mynet busybox
8486e5a8dd8df0969a25b934bac8a3ebd7c040a91816403a2e3ddb067e559aa3Once they are started, we can inspect the network to see all of our settings, as well as the IPs that were allocated for the two containers we just created:
$ docker network inspect mynet
[
{
"Name": "mynet",
"Id": "2ce5e00010331ec9115afd0adfc972a3beb530d3086bea20932e5edc85cfa4de",
"Created": "2020-05-21T13:23:45.13078807+12:00",
"Scope": "local",
"Driver": "ovs",
"EnableIPv6": false,
"IPAM": {
"Driver": "default",
"Options": {},
"Config": [
{
"Subnet": "172.12.0.0/24",
"IPRange": "172.12.0.8/29",
"Gateway": "172.12.0.1"
}
]
},
"Internal": false,
"Attachable": false,
"Ingress": false,
"ConfigFrom": {
"Network": ""
},
"ConfigOnly": false,
"Containers": {
"205e47b076195513a54b98ea78c4c449c5ac403371508e457a6631f64c0c3596": {
"Name": "cool_hawking",
"EndpointID": "3190227dd6ae96568c18101cbbd55c11b0b9d62fd907784d29b64cc8df7ce1b7",
"MacAddress": "",
"IPv4Address": "172.12.0.8/24",
"IPv6Address": ""
},
"8486e5a8dd8df0969a25b934bac8a3ebd7c040a91816403a2e3ddb067e559aa3": {
"Name": "vibrant_haibt",
"EndpointID": "7154d47c2db8820990538c9a673a319c0c0c4afd32e18d68fa878f1ce5a723b0",
"MacAddress": "",
"IPv4Address": "172.12.0.9/24",
"IPv6Address": ""
}
},
"Options": {
"ovs.bridge.controller": "tcp:127.0.0.1:6653",
"ovs.bridge.dpid": "0x1",
"ovs.bridge.mode": "nat"
},
"Labels": {}
}
]If we go into one of the containers we can also verify the network matches what we expect:
$ docker exec -ti 8486e5a8dd8d ifconfig
eth0 Link encap:Ethernet HWaddr DE:BC:94:F9:63:33
inet addr:172.12.0.9 Bcast:172.12.0.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:9 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:726 (726.0 B) TX bytes:0 (0.0 B)Here’s an example minimal faucet.yaml that connects the OVS bridge to Faucet. We’ve supplied a range of 10 ports on the same native VLAN, which the first 10 containers attached to the network will get assigned to.
dps:
docker-ovs:
dp_id: 0x1
hardware: Open vSwitch
interfaces:
0xfffffffe:
native_vlan: 100
interface_ranges:
1-10:
native_vlan: 100Note: the interface 0xfffffffe is needed specifically for only the "nat" mode of our plugin with OVS. Now you can monitor and control the network your containers use with Faucet!
Network devices are just computers.
Obligatory XKCD.
In this post, I thought it would be efficient to describe my own personal motivations for contributing to SDN generally and FAUCET specifically, and why I personally believe they’re both good things. You could say in the New Zealand vernacular, that these are my “reckons.” I’m responsible solely for them – I do not speak for others (including the FAUCET Foundation). I don’t have any expectations around changing minds – this is more about providing a convenient reference point, for my particular point of view (and I don’t even claim that it’s a unique view).
My intended audience (if I have any audience!) is those in the networking and related industries. In the wider computing industry what I have to say will sound very strange (what do you mean you have to explain that computers are computers and that less complex code is better than more complex?).
I can summarize my view in one paragraph:
SDN is just a reminder that network devices are computers. Specifically, we are reminded that we have the power to change the software those devices run – and that software can be smaller, less complex, and do the job of connecting computers together better than the software we run on network devices now.
Everything else I have to say, logically follows from this point. The first router (the IMP) was a repurposed computer. The first Cisco router was correctly called a server (the Cisco AGS). Network devices are still computers now. The function of network devices – to connect computers together – does not make them different from other computers. Just as smart phones, autopilots, and Commodore 64s are computers, so are network devices. They often have hardware features to enable good performance (moving data from one place to another with low latency), but such role-enabling hardware features (high performance video cards, CPU caches, DSPs, etc) are commonplace among all kinds of computers and don’t make them non-computers thereby.
Surprisingly (to me at least) it has been argued that SDN networks will “inevitably” be complex. There is no physical law requiring you to write the most complex program you possibly can, just because a computer is available (though it can be fun or even profitable to do so, for one reason or another). If you have a less complex computer program that accomplishes the task of a more complex program, and the less complex program does that task better (e.g. faster, more reliably and with less resources), the less complex program is desirable (it can run on less complex computers, and it is easier to understand and debug). Again, SDN just reminds us that there is a choice.
There is really only one other substantial point to make. That is, the administrative boundaries currently dividing the computer network industry – network user, network operator, and network vendor – arise from business, not technical reasons. In computer industries generally, these boundaries have been fluid over time. Now, and for some time, it is quite usual for a computer user to have the expectation that they can program their own software if they want to (even if most don’t). In fact there are many groups in society specifically encouraging more people to program computers, and most computers have freely available development environments and tools.
The network industry on the other hand has grown up with a contradictory practice – that network operators shall not program their network devices (sorry, computers) themselves – ever. Network operators can have some influence over the specifications for the software on the computers (standards groups, paying vendors for features, etc). The industry has created a special kind of computer operator – a network engineer. This kind of computer operator, often with considerable skill, operates network devices within the constraints of (generally) commercially provided software. That’s it. A network engineer (sorry, computer operator) isn’t expected to write any code, though some do – and by and large that code in turn manages the vendor provided code in a way that’s more efficient for the operator’s employer (e.g. allows configuration changes to be deployed faster).
I argue this is wrong. Since network devices are computers, and the market for user programmable computers for other users doesn’t appear to be a small one, why shouldn’t the network operator have the option to program their own computer if that’s best for them? Why does the computer (sorry, network device) manufacturer get to have the final say in how their computer is programmed? Since we know they just manufacture computers, and given everything above – the answer can only be that the restriction exists for non-technical reasons. And not because that approach is somehow best for all involved (including, not least, the end users of the network).
So what’s any of this got to do with FAUCET? FAUCET illustrates exactly how SDN reduces complexity. It’s small – low 10klocs and runs on hardware ranging from old school Broadcom to P4 while giving you the exact same abstraction and forwarding behavior (because, the – small – forwarding algorithm isn’t inside each of the switches anymore – nor does it need to be). How? By effectively refactoring all the common code off of the individual switches it controls and dropping all the other unneeded features. Because you can do that with computers.